

This week's finds in genomic life: Genomes and autoencoders, regulating AI in medicine , and more
Five links for the weekend on AI, biomedicine, and the NIH budget.
1. The genome as a generative model
Understanding how genotype relates to phenotype has been one of the fundamental challenges in biology for more than a century. More explicitly, the challenge is to understand how the linear DNA sequence of the genome encodes the necessary information to robustly generate an adult organism, and how variation in DNA sequences leads to differences between members of the same species.
Kevin Mitchell (at Trinity College Dublin, and author of multiple books on neurobiology, including most recently Free Agents) and Nick Cheney (at the University of Vermont) have a thought-provoking piece in Trends in Genetics that addresses these questions by working out an extended analogy between the genome and generative neural networks, specifically variational autoencoders (VAEs). I like this comparison because it is a very specific way of seeing the genome as a compressed representation of an organism that is decoded during development.
To motivate their argument, Mitchell and Cheney point out the flaws in the more common metaphors of the genome–as a program, a recipe, or a blueprint. Here they are on the genome as a blueprint:
First, an architectural or engineering blueprint is isomorphic with the desired product, that is, distinct parts of the blueprint correspond directly and specifically to distinct parts of the product. In this way, the blueprint concept is almost preformationist, with the genome containing a direct mapping of the final product. Second, a blueprint does not usually contain instructions on how to build the object in question, it only has information on what it should look like when completed. This clearly leaves a major question unanswered: how are the processes of development specified so as to yield the desired outcome? And finally, a blueprint typically specifies an object in such detail as to be effectively deterministic, leaving little room for the kind of variability in developmental trajectories and outcomes that is typically observed even in genetically identical organisms raised in highly controlled, effectively identical environments.
A vivid example of the genome as a compressed representation is the single-celled zygote, the state in which we all began.
What does the genome encode directly? Sequences of proteins and functional RNAs, as well as regulatory elements (whose encoding in DNA sequences is still not well understood). In all of these sequences, Mitchell and Cheney say that the key feature that is encoded is “differential affinities.” Proteins and RNAs function by forming selective interactions with other proteins, RNAs, DNA, and small molecules. Back in a 1958 paper, a few years before the genetic code was cracked, D.L. Nanney made a similar argument, that the genome is a “library of specificities.”
Mitchell and Cheney argue that, like a VAE which reconstructs new images or other outputs by running the compressed information through a series of higher dimensional neural network layers, genomic information is realized through a succession of cell types as development and differentiation occur. I haven’t considered this enough, but I’m not sure how induced pluripotent stems cells and direct reprogramming of one type of cell into another fit into the analogy of a compressed representation being decoded through a series of developmental states. With direct reprogramming, you skip directly from one state to another.
Mitchell and Cheney do make it clear that they’re not arguing for a perfect analogy between any kind of neural network and development. The real strength of their conception is that it lets them set up a more specific, formalized model.
There is a lot more in the piece, including a section on evolution as the encoder in the VAE analogy. It’s worth a read for anyone interested in ways to conceptualize the relationship between genotypes and phenotypes.
2. Why different mutations in the same transcription factor genes have such different clinical outcomes
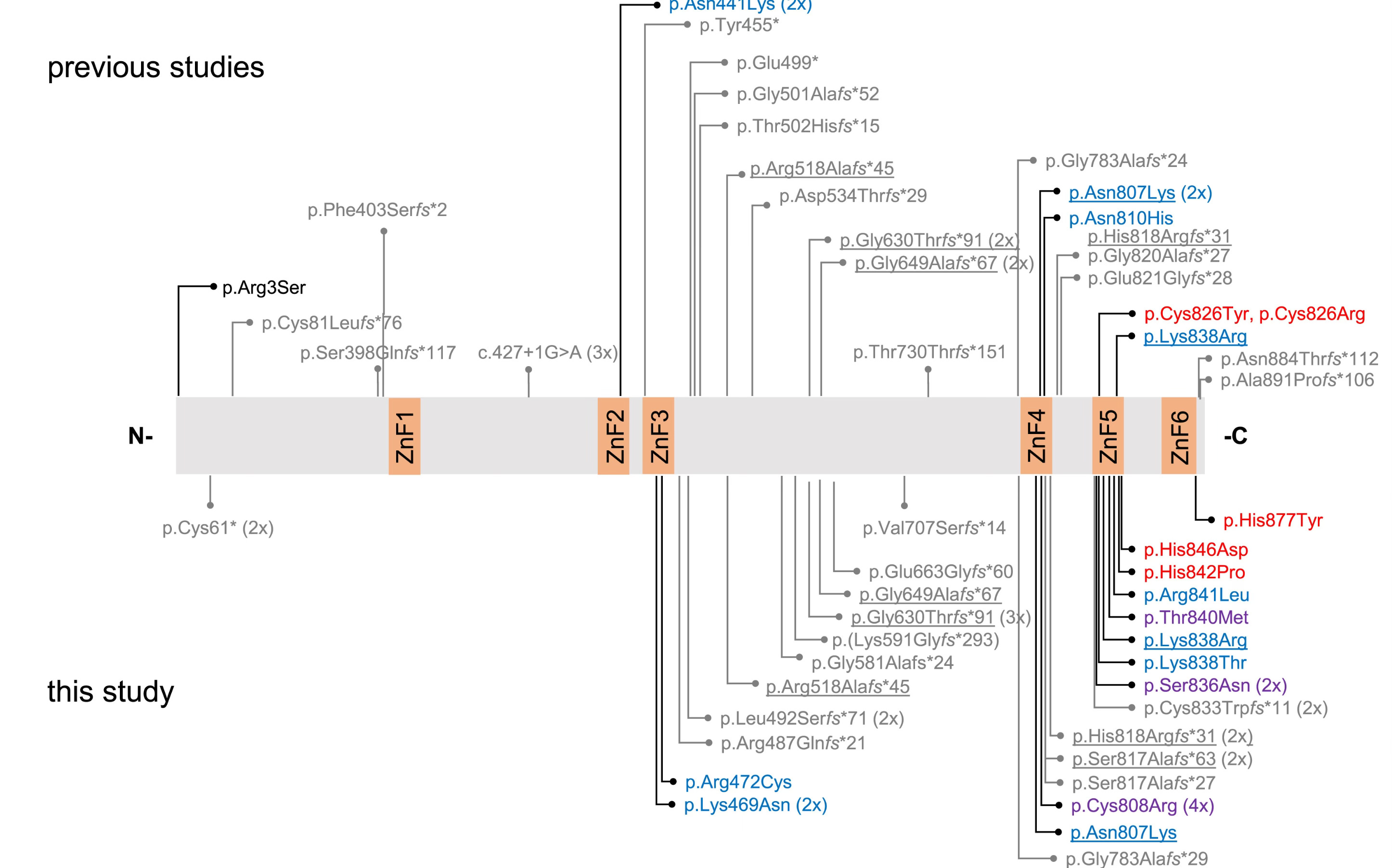
Speaking of cell biology being largely about differential affinities and specificities, a new paper in the American Journal of Human Genetics shows that the phenotypic impact of mutations in the gene for the transcription factor BCL11B corresponds to whether those mutations alter the affinity or specificity of this protein’s binding to DNA.
Mutations in BCL11B cause a variety of developmental syndromes that feature cognitive, morphological, and immunological problems. The challenge is that, since all of these mutations occur in the same gene, it is very hard to predict which mutations will have severe versus mild outcomes.
The scientists analyzed pathogenic or likely pathogenic BCL11B mutations from 92 patients, and found that they could group patients into three clinical subtypes based on where in the gene the mutation occurred. Interestingly, mutations at positions in BCL11B that contact DNA, and which are responsible for its DNA binding affinity or its specificity, resulted in the more severe and variable clinical outcomes. Mutations elsewhere in the protein were relatively mild.
The results indicate that the most damaging mutations are those that change the ability of BCL11B to target the right set of genes, rather than simply attenuating its ability to activate genes. This alone isn’t so surprising: if you fail to turn on the right genes, or turn on the wrong ones in a particular context, bad things happen. What this paper shows, and what I think is less appreciated, is that different mutations in the same transcription factor will not affect all of its target genes in the same way. The different clinical outcomes probably reflect the fact that each mutation affects different sets of targets, with different biological consequences. (We made a similar argument in a paper last year.)
3. Regulating AI in medicine
Former FDA Director Scott Gottlieb has a written a thoughtful piece about how AI in medicine should be regulated. It’s obvious to everyone that the incorporation of AI into health care is inevitable, because there are clearly enormous potential benefits, but there are also enormous risks. The issue facing everyone, but especially the FDA as a regulatory agency, is how to balance the risks.
Gottlieb is worried that AI tools “with advanced analytical capabilities” will be automatically classed as medical devices by the FDA, under recent change in its guidelines. Why is that a problem? Because it would prevent new AI capabilities from being incorporated as add-ons to existing software tools, like electronic medical record (EMR) systems or other software intended to support clinical decision making. If an AI tools is classified as a medical device, that means EMR developers would be incentivized to exclude them, because it brings a higher level of regulation to bear on the entire software suite:
If these tools are classified as medical devices merely because they draw from multiple data sources or possess analytical capabilities that are so comprehensive and intelligent that clinicians are likely to accept their analyses in full, then nearly any AI tool embedded in an EMR could fall under regulation. The risk is that EMR developers may attempt to circumvent regulatory uncertainty by omitting these features from their software. This could deny health care clinicians access to AI tools that have the potential to transform the productivity and safety of medical care.
Gottlieb notes that the 2016 21st Century Cures Act was written to avoid exactly this kind of outcome, in which digital health tools are regulated not based on their clinical use but rather their analytical sophistication. AI tools that don’t make autonomous diagnoses or treatment decisions shouldn’t be treated as medical devices.
The rapid growth of EMRs in clinical practice has opened up a lot of potential to improve health care, by letting different doctors for the same patient easily share information, and by facilitating medical research with very large cohorts and high statistical power. The ability of AI tools to make recommendations based on the synthesis of different data sources is another way EMRs could lead to better care. That will only happen if the incentives are there to develop these tools.
4. What’s the return on investment for the NIH budget?
The NIH has been a target for the new administration’s firing and spending freezes. Despite a court ruling that the NIH needs to spend the money appropriated by Congress, the works are still gummed up and study sections have by and large not been able to review new grant submissions. This is a frustrating and completely unnecessary self-own; the U.S. benefits by being the place where much of the world’s biotechnology is invented. (Though there are ways we could benefit more–choices made by our government have left us with higher drug prices than elsewhere.)
Any time the NIH or NSF or NASA budgets come up, the perennial question returns to the discourse: what do we get for our research dollars? One of the best places to find an answer to that question is at Matt Clancy’s New Things Under the Sun Substack page, where he has a continuously updated piece on the ROI of government spending on R&D. His answer:
This is very challenging to estimate, but a variety of research points to an additional dollar of government sponsored R&D generating $2-$5 in benefits via economic growth.
If you want the details of the calculation, with references to the literature on this subject, check it out.
As someone who has received multiple NIH grants, there are a few points about these grants I think are worth highlighting:
I, and most colleagues that I am aware of, value the trust placed in us by the taxpayers whose money funds our labs. The NIH funds our work in order to benefit everyone through advances in knowledge and technology, and I take that seriously. We all should–the knowledge generated by science should benefit everyone, regardless of partisan affiliation, identity, etc.
Grant budgets are tight. There is not a lot of slack in a standard NIH R01. You need at least two funded R01s to run a modestly-sized lab these days. It does not cover all of costs of research, some of which are in fact borne by the universities and hospitals we work for. This is not intended as a complaint. The point is that government-funded scientists have very strong incentives to spend their grant money efficiently, because if you waste it you won’t have enough to accomplish your scientific aims.
Over the decades, the U.S. has developed world-leading scientific research institutions, and, even though there are some aspects many of us would reform, we are still the place where scientists from around the world want to work. We have our edge in biomedical research thanks to a longstanding, bipartisan commitment to government-funded science. This is an enormous national resource that we shouldn’t recklessly discard, and we shouldn’t assume it can easily be rebuilt if we break it through ignorance and carelessness.
On the related issue of indirect costs paid by the NIH to universities, Harvard geneticist Sasha Gusev, who write The Infinitesimal, has a detailed discussion of indirect costs and much more. Indirect costs have been a big source of misunderstanding:
A research contract is work: when the government hires General Dynamics to build a jet, they pay for the hangar; and when the government hires a university to study cancer, they pay for the lab space.
In his conclusion, which I agree with, he doesn’t mince words:
What happens while everything is shut down? Excellent funding applications that took months to develop are summarily rejected because their mechanism was cancelled; high-scoring grants are passed over for funding because the review council cannot meet; effective drugs are delayed for approval because the FDA has a staff shortage; longitudinal cohorts that have been collected for decades collapse and their data becomes polluted; and — most importantly — the next generation of talented people who planned to pursue research for the public good are cruelly let go or not hired and drift away. In most cases we may not know for years that a study or a dataset was important and should not have been abandoned. And because the whole thing is being conducted without rigor, even when cuts increase efficiency they will be confounded by all the other functions grinding to a halt.
5. What is convolution and why is it important in deep learning?
Convolutional neural networks are everywhere these days, and they often have impressive predictive power compared to more standard statistical models, like linear regression. So why is a convolutional neural network so special? If you’ve wondered just what convolution is, Christopher Olah has a superb series of blog posts on the concepts behind neural networks, including convolution. It was written in 2014, but it’s still a great explanation of the idea.
If you’ve had any statistics, you are probably familiar with some of the ideas behind convolution. If you have two random variables, each with their own probability density function, what is the probability density function of the product of these two variables? Let’s take a discrete case: if I roll two dice, a six-sided die and twenty-sided die, what is the probability that the product of the two rolls is 18? Well, if you roll a 1 with the first die, then you only get 18 if you roll 18 on the second die. But you could also get 18 by rolling a 2 and a 9, etc. You get the idea. To see why this matters, check out Olah’s post.
OK, there was one other piece of big news this week in the world of AI and biology. The Arc Institute and Nvidia announced a new foundation model, Evo-2. I’ll have some things to say about it next week, along with some commentary about what standards we should have for judging the performance of generative DNA models. Have a great weekend.