

This week's finds in genomics and beyond
Some genomics and general science reading for your pre-holiday weekend
Here are five items that caught my eye this week:
1. Genomic foundation models aren’t there yet
One question that comes up in recent discussions about AI is what happens when the big large language models run out of training data? There are concerns that progress is starting to slow since companies like Google and OpenAI have already used up just about all of the available text on the internet.
There is a parallel concern about large DNA language models, which haven’t made as much progress as one might have expected. Two recent papers benchmark these models and find that, despite the fact that they are the biggest AI models in genomics, they don’t compare favorably to humble CNNs trained on smaller datasets for specific tasks.
In one paper, out in Nature Methods, the team at InstaDeep trained transformer models on different datasets and then benchmarked their performance on a variety of tasks. In the paper, they give a glass-half-full interpretation of results that show models with 2.5 billion parameters, trained on hundreds of thousands of genomes, often don’t do worse on specific tasks than smaller specialized models. They generally don’t do better either. For example, a 2.5 billion parameter model trained and then fine-tuned to predict activities of regulatory sequences in a massively parallel reporter gene assay didn’t do any better than a small CNN:
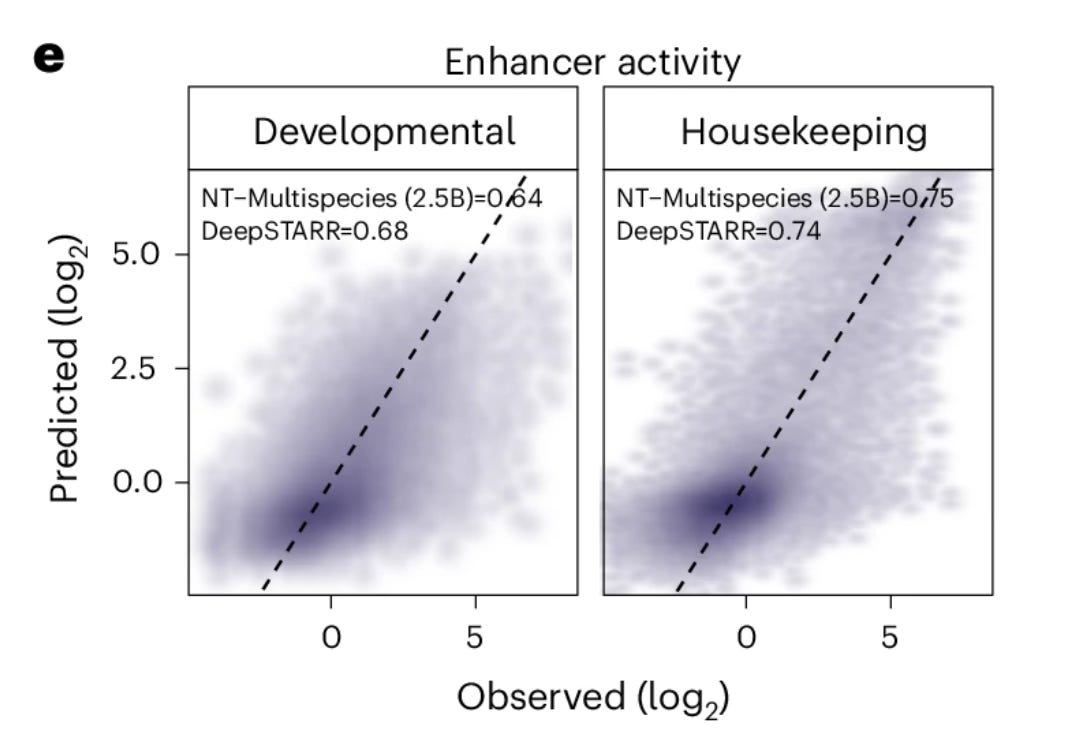
Despite these disappointing results, this a well-done study that presents a clear, systematic evaluation of these models.
A second DNA language model benchmarking paper was just posted on arXiv by Anshul Kundaje and his lab, at Stanford. This is also a nicely-executed study that includes a worthwile discussion of the state of the field. Their top-line conclusion is that “current annotation-agnostic DNALMs exhibit inconsistent performance and do not offer compelling gains over alternative baseline models for most tasks, despite requiring significantly more computational resources.” So yeah, we’re not there yet.
I’ll highlight a critical point from their discussion that, at least in the circles I move in, is one that is increasingly recognized as a challenge: the genome itself isn’t necessarily the best training data for the models we want:
Although DNALMs successfully discriminate regulatory DNA from background sequences, they appear to learn incomplete repertoires of regulatory sequence features. This limitation likely stems from the sparsity and the uneven distribution of regulatory features; regulatory elements constitute only 10-20% of the human genome, and certain classes of regulatory features occur at substantially different frequencies.
2. A tool to measure the activity of a cell’s regulatory factors
Transcription factors are the key regulators of a cell’s identity, since they direct the expression of the right repertoire of cell type-specific genes. To know which transcription factors are active in a cell type people typically look at RNA-seq data, but this only tells you something about the amount of transcription factor present in a cell and not its level of functional activity.
Bas van Steensel’s lab, at the Netherlands Cancer Institute, has a paper out in Cell Systems that describes how to use multiplexed reporter gene libraries as a tool to read out transcription factor activity in a cell. They came up with a scheme to design optimal sensors of transcription factor activity, and because the libraries are multiplexed, you can read out the activities of dozens of factors.
3. Everything you ever wanted to know about commercial single cell technologies.
One of my plans over the holiday break is to get up to speed on some areas I should know better than I do, including the latest single-cell omics technologies. Fortunately, the latest issue of Cell Genomics has a comprehensive, open access review of single-cell genomic and epigenomic assay technologies. Even better, this is merely the introduction to what they call a “living review”: a Substack page at sctrends.org discussing all things related to single-cell and spatial omics technologies. (Noted: find a way to promote your Substack by writing a paper about it…)
4. The laws underlying the physics of everyday life are completely understood
In 2010, the physicist Sean Carroll wrote what is probably one of my favorite blog posts of all time, in which he claimed that “the laws underlying the physics of everyday life are completely understood.” He said:
A hundred years ago it would have been easy to ask a basic question to which physics couldn’t provide a satisfying answer. “What keeps this table from collapsing?” “Why are there different elements?” “What kind of signal travels from the brain to your muscles?” But now we understand all that stuff. (Again, not the detailed way in which everything plays out, but the underlying principles.) Fifty years ago we more or less had it figured out, depending on how picky you want to be about the nuclear forces. But there’s no question that the human goal of figuring out the basic rules by which the easily observable world works was one that was achieved once and for all in the twentieth century.
This claim caused a little controversy, but I like it because it pushes back against a view of science that people may have picked up from Thomas Kuhn (or Larry Laudan for a deeper cut), namely that scientific paradigms are always going to change and that today’s theories are almost certainly going to be discarded by scientists of the future. I don’t think that is uniformly true. In biology we’ve figured out the basics of mammalian sexual reproduction (two haploid gametes fuse to form a diploid zygote). We have a good understanding of the structure of DNA and why that structure enables DNA to act as a template for transcription and its own replication. Not everything in science is going to be obsolete.
I can’t speak to the physics, but Carroll wrote an interesting paper laying out the details of his claim. (It was posted in 2021 but I didn’t see it until this week.) If you’re interested in this discussion, it’s worth at least skim, even if you don’t have a background in quantum mechanics.
5. Are we living in a simulation?
Speaking of philosophy and science, here’s one more interesting paper, this one by the philosopher Peter Godfrey-Smith, who is one of the most interesting philosophers of biology working today. He takes on David Chalmer’s best-selling book Reality+ and gets into questions like the substrate independence of minds.
6. Three history of science books that directly address philosophy
It’s getting a little late to make holiday book recommendations, but here are three I enjoyed, one well known, and two less familiar. I enjoy books that present a careful history of some aspect of science, and then use that history to directly address big questions in philosophy of science.
David Wotton, The Invention of Science. This book got quite a bit of attention when it came out in 2015. I’ve read more than a dozen books on the Scientific Revolution and this is easily my favorite. Wootton argues that science was not a gradual evolution from earlier natural philosophy, but was instead a specific invention of the long 17th century. He makes his case by analyzing the emergence of language of science. For example, when did people start using the words discovery, experiment, and fact, and in what context were they using them? This proves to be an extremely effective way at understanding what the scientists of the 17th century thought they were up to. (They didn’t use the word ‘scientist’, but they used other words that captured the same idea.)
Stephen Brush, Making 20th Century Science. Historian Stephen Brush asks, what is more convincing to scientists, a successful new prediction or an explanation of some long-standing anomaly? To answer this question, Brush examines the history of how scientific consensus was achieved for major theories developed in the 20th century. He traverses quantum mechanics, organic chemistry, general relativity, the Big Bang, the hereditary role of chromosomes, and the Modern Synthesis of evolution and genetics. You may have thought that Eddington’s famous 1919 eclipse expedition to test Einstein’s theory of general relativity is a classic case of a successful new prediction persuading scientists, but Brush explains that it took nearly five more years of careful measurements before most of the physics community came around. In general Brush’s answer is that both prediction and explanation can be persuasive in different contexts, but there is more to it. To get the full, nuanced answer, read the book.
Elof Axel Carlson, How Scientific Progress Occurs. This concise book reviews the history of cell and molecular biology, with the aim of contrasting scientific progress in biology with Thomas Kuhn’s model of paradigm shifts. Carlson argues that biology is much more incremental and, as far as he can see, basically never involves paradigm shifts. It’s a provocative book with some great history - history that really anyone working in the biomedical sciences should know.