

This week's finds: Bad AI is bad science, autism versus cancer mutations, open drug development, etc.
For the weekend, this week's finds in genomics and more, with a science fiction recommendation.
1. Bad AI will be bad for science
In this week’s issue of Nature, computer scientists Arvind Narayanan and Sayash Kapoor warn about the potential for bad AI to set science back. Narayanan and Kapoor are the authors of AI Snake Oil, a book warning about AI hype, and one that I included in my recent post of recommendations for learning about AI. The authors suggest that an overreliance on AI in science is bad for two reasons.
The first is incompetence: like conventional statistics, AI can be used badly by people who lack the training or commitment to use it properly. “Machine-learning modelling is the chainsaw to the hand axe of statistics — powerful and more automated, but dangerous if used incorrectly.” One of science’s dirty secrets is that many, if not most scientists have inadequate formal training in statistics. That includes me–I never took a stats course or even a course with a serious statistical component. Bad statistical practices like p-hacking, due in part to poor training, has caused pervasive reproducibility problems in some fields. Widespread, inexpert use of AI has the potential to be much worse. Narayanan and Sayash write that
[E]rrors are becoming increasingly common, especially when off-the-shelf tools are used by researchers who have limited expertise in computer science. It is easy for researchers to overestimate the predictive capabilities of an AI model, thereby creating the illusion of progress while stalling real advancements.
One of the critical problems is “leakage”, which means that the test dataset is not fully independent of the training data. If information is shared between test and training data, AI models will score well by just memorizing the training data, and then fail to generalize to other datasets when someone tries to use the model for another analysis. The authors created a list of recent studies across disciplines that identify common problems with data leakage in published research. Everyone should read a few of those papers to learn about problems in their field.
It is common in genomic AI modeling to evaluate models on held-out data from the same experiment, such as RNA reads from a subset of chromosomes in a single RNA-sequence experiment. While this may not formally count as data leakage, I don’t think it’s great for the field to almost exclusively evaluate AI models on test data taken from the same experiments as the training data. We should hold ourselves to higher standards and evaluate our models either on independent benchmark datasets, or, if feasible, just do another experiment to generate your test data.
The other problem that Narayanan and Kapoor worry about this that we’ll confuse AI predictive success for real conceptual progress:
AI excels at producing the equivalent of epicycles. All else being equal, being able to squeeze more predictive juice out of flawed theories and inadequate paradigms will help them to stick around for longer, impeding true scientific progress
In other words, we shouldn’t outsource our thinking to AI models. This gets to the ultimate goal of scientific theories, which, aside from their practical uses, is to describe nature in a way that is comprehensible by humans. Science is for human minds. Centuries of scientific progress show that a program of ruthless experimental testing of big ideas about the world leads to new discoveries. In genomics, AI can be a powerful discovery tool that will help us learn how genomes function, but in the end what we want is an understanding that explains how DNA sequence, interacting with other molecular players, leads to cellular and organismal phenotypes.
Aside from a commitment to the empirical foundations of science, one of the most important solutions to the problems raised by Narayanan and Kapoor is education. Everyone, especially everyone who does work or aspires to work in science should learn about AI.
2. Different diseases, same genes: mutations in cancer and autism
My WashU Genetics Department colleague Tychele Turner and her collaborator Rachel Karchin of Johns Hopkins have a paper out in Cell Genomics looking at genetic variation genes that are associated with both cancer and neurodevelopmental disorders (NDDs) like autism. They sought to learn why mutations or genetic variants in the same genes can lead to different outcomes (cancer or NDDs). They looked at missense variants, whose effects are often difficult to figure out because these variants cause single amino acid changes in a protein, as opposed to larger, more obviously damaging mutations.
The challenge with any genetic variant analysis is that there are many variants that exist in cancer or in individuals with NDD that have no effect whatsoever on disease. Thus geneticists try to come up with clever ways to sift the wheat from the chaff. In this case, Turner and Karchin hypothesized that causal variants for either NDD or cancer would cluster in similar parts of the protein. That is, if we take a protein that plays a role in both cancer development and NDD, we would see that mutations that genuinely lead to NDD would disrupt the protein in similar ways. Mutations that cause cancer would affect the same protein but in different a way, and thus would cluster in a different part of the protein. That is indeed what they found:
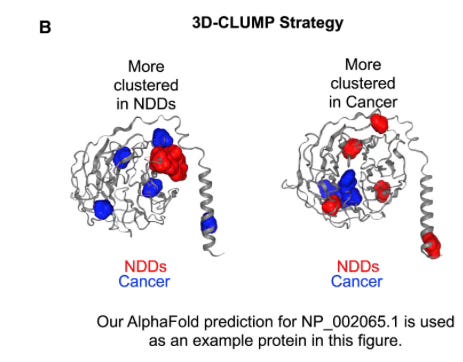
In the figure above, showing two views of the same protein, blue represents sites of mutations found in cancers, while red represents genetic variants found in NDD patients. You can see that the sites of the clustered mutations are different for different diseases, suggesting that causal mutations for each disease affect different parts of the protein.
The study illustrates the power of AI for discovery in genomics–the scientists used AlphaFold structure predictions to perform their 3D clustering analysis. Looking at the 3D structure is important because mutations that may be distant in the linear sequence of the protein may be close together in folded, 3D structure. The big takeaway is that while both NDD and some cancers are associated with missense mutations in the same gene, the patterns of missense mutations, at least for some genes, differ between the two diseases. The same gene can be damaged in different ways and lead to dramatically different outcomes.
3. Data problems for AI models in drug development
In 2023, a group of news organization sued OpenAI and Microsoft for copyright infringement, claiming that GPT was trained on millions of copyrighted works without permission from the copyright holders. The suit highlights one of the challenges of cutting edge progress in AI: you need enormous amounts of data, on a scale that couldn’t possibly be generated by one organization. At the same time, it’s probably not feasible in most cases to pay for access to all of the data you need, when that data is scattered among many different owners. If the data you need is a bunch of online content, then, like OpenAI and others, you just scrape everything you can get from the internet and figure you can settle the lawsuits later.
But this strategy doesn’t work if your AI needs to be trained on big datasets obtained from experiments, which aren’t always so east scrape from the web. A comment piece in the latest issue of Science highlights the lack of large, high quality open datasets that could be used to advance AI methods for drug discovery. Not even the largest pharmaceutical companies will, at least any time soon, have their own datasets at the scale needed to implement truly cutting-edge AI. The whole drug discovery enterprise would be better off if the players involved collectively supported the development of high quality, open datasets that would allow the field, including industry AI teams, to innovate:
To help AI mature, developers need nonproprietary, open, large, high-quality datasets to train and validate models, managed by independent organizations.
The authors draw an analogy to the bad old days of gene patents, when a lot of useful genomic data was locked up in proprietary databases. Open genomic data has spurred an enormous amount of innovation, and the same thing could happen for AI-based drug discovery if academic and industry players worked together to contribute open data. There is an opportunity here to avoid the problems at the center of the news versus OpenAI lawsuit, and to make deliberate decisions about how to support AI innovation in this field. While I’m on board with the open datasets, I do think the authors of the opinion piece underestimate the impact of task-specific AI models that can be trained on smaller datasets. Not everything needs to be GPT or AlphaFold.
4. Can statistical models really just regress out all confounding factors?
Some time ago I read a piece by Brown University health economist Emily Oster that has stuck with me. I can’t remember the original piece, but there is a 2024 version on her blog that confronts a critical question about epidemiological studies: is it really possible to control for all of the confounding factors in a statistical model? Oster suggests that confounding is much worse than we typically think.
There are many common examples epidemiological claims that are a longstanding source of controversy, such as the question of whether moderate drinking is better or worse than no drinking, whether there is a risk between certain foods and cancer, etc. For example, are people who drink more at a higher risk for cancer because of the alcohol, or because those who drink more also tend to smoke? To answer that, epidemiologists try to control for smoking (and age, sex, exercise, etc.) in their analyses of what alcohol’s effects are.
Oster gives another example of this kind of reasoning:
[T]he reason we know that the processed food groups differ a lot is that the authors can see the characteristics of individuals. But because they see these characteristics, they can adjust for them (using statistical tools). While it’s true that education levels are higher among those who eat less processed food, by adjusting for education we can come closer to comparing people with the same education level who eat different kinds of food.
But what about controlling for the variables that you don’t see? This is of course something that is well known to statisticians, called residual confounding. Oster says:
We all agree that this is a concern. Where we differ is in how much of a limitation we believe it to be. In my view, in these contexts (and in many others), residual confounding is so significant a factor that it is hopeless to try to learn causality from this type of observational data.
She argues that many of the differences among human study subjects that statisticians treat as random (after controlling for confounders) are actually not random. They are much more highly correlated with confounders than scientists think and, importantly, subject to social feedbacks in a way that is not sufficiently appreciated.
Oster gives an example of studies looking at a link between breastfeeding and intelligence:
The link between breastfeeding and IQ is a good example. This is a research space where you can find many, many papers showing a positive correlation. The concern, of course, is that moms who breastfeed tend to be more educated, have higher income, and have access to more resources. These variables are also known to be linked to IQ, so it’s difficult to isolate the impacts of breastfeeding.
So what happens to this link when you control for confounding variables? She points to a 2006 paper that controlled for parent IQ and demographics, as most papers do. But then they kept adjusting for additional effects, such as within family effects (comparing siblings, only one of whom was breastfed). After these adjustments, the correlation between breastfeeding and IQ disappeared entirely.
How bad is this problem across all observational studies in economics, health, sociology, etc? Oster thinks it’s very bad, “that a huge share of the correlations we see in observational data are not close to causal.” These poor studies lead to bullshit headlines and bad media coverage, and populace that is confused by a series of flip-flopping scientific claims about moderate drinking, processed foods, breastfeeding, etc. I’m inclined to agree–we should be very skeptical about the ability of scientists to statistically control for all of the relevant confounding variables in observational studies. While in some cases observational studies are the best we can do, being ‘the best we can do’ should not be an excuse to simply accept flawed evidence.
5. The 100-year old science fiction of the Radium Age.

To round off the newsletter, here’s something for fans of science fiction. Most people who are into science fiction are aware of the so-called Golden Age, when pulp magazines dominated the genre. This ran largely from the 1930’s (John Campbell became editor of Astounding in 1937) through first decade or so after WWII when mass market paperbacks took over. But before the Golden Age was the fascinating Radium Age, which was both more innovative and less male-dominated than what came later. Science fiction of the first quarter of the 20th century, called the Radium Age by publisher Joshua Glenn and characterized by him as filled with a “dizzying, visionary blend of acerbic social commentary and shock tactics.” Most of the classic plots and character types that we ascribe to the Golden Age were already present in the Radium Age. There is a long list of really interesting works by women of this era. Consider the plot of a book written in 1909:
When Mary Hatherley, an intrepid British explorer, is kicked in the head by the camel she was riding through the Arabian desert, she finds herself transported to what seems to be an alternate version of Earth. Arriving in Armeria, she discovers a society in which the very concept of gender is unknown.
How about a 1935 Bengali cult classic describing lost race of Bengali supermen in Uganda?
The era also includes a post-apocalyptic plague novel by Jack London, a satirical cyborg novel, H.G. Wells’ 1913 novel about nuclear war, a 1926 eugenic dystopia, and much more. MIT Press is publishing many of these works, so if this is sounds interesting to you, go check out the series.