

Technologies That Made The Human Genome Project Possible
An oral history of key, early technological advances made in St. Louis that first "instantiated" genomics.
Note: This post exceeds the email length limit for Substack. To read the full transcript of the talk presented below, click through to the post on the web. The highlights are presented first.

Last spring, my colleagues and I organized a symposium in honor of our colleague Gary Stormo, a pioneer of computational biology who (nominally) retired last year. (He still has some papers in the works.) The outstanding closing talk was given by Mark Johnston, former chair of the Washington University Genetics Department and now emeritus chair of the Department of Biochemistry and Genetics at the University of Colorado School of Medicine. In his talk, Mark made a bold claim: that our Genetics Department here in St. Louis was the “founder” of genomics in its modern sense. Mark argues that it was here — specifically on the eighth floor of the McDonnell Sciences building where the Genetics Department was housed— that genomics was first instantiated.
Those from other institutions who are less partisan than I am may dispute this claim, but no matter where you come down on it, Mark Johnston’s talk is a fascinating oral history of the technological advances that were needed to make genome sequencing possible. (Read Mark’s talk and you’ll learn about the early St. Louis careers of several important figures who made Seattle’s University of Washington a genomics powerhouse. Our department also trained the current director of the National Human Genome Research Institute.) Imagine a scientist in the early 1980’s considering the daunting prospect of sequencing the entire human genome. Sequencing very short segments of DNA was a tedious process that involved manually examining bands on a polyacrylamide gel. Sequencing hundreds of base pairs was daunting, and the technology to sequence billions of base pairs did not exist.
Today, I can submit my sample to our sequencing core and get back a few hundred billion bases of sequencing in a couple of days. This capacity is, and will continue to be transformative, but how did it originate? Mark Johnston covers some of the critical early developments that anyone interested in genomics should learn about. Below I’ve highlighted the key landmark papers/technologies that Mark presents in his talk. If you read these dozen or so papers, you will have an excellent understanding of the key technologies that made the Human Genome Project possible. You can watch the video and read over the annotated and lightly edited transcript below. Mark was the person who drew me to Washington University few years after the draft human genome sequence was published. In the talk below you can hear his wonderfully dry sense of humor, his intelligence, and his very clear sense of the history of this field. It’s an inspiring story
Landmark 1: Restriction fragment clone mapping
Genomes aren’t sequenced in order, from the start to end of individual chromosomes. Your sequencing data comes in shorter fragments. To sequence a genome, you need a map. Work by Maynard Olson at Washington University in St. Louis on S. cerevisiae, and complementary work at the MRC in Cambridge mapping the genome of C. elegans showed to create these maps.
Random-clone strategy for genomic restriction mapping in yeast, Olson, et al., PNAS, 1986 Oct; 3(20):7826-30.
Toward a physical map of the genome of the nematode Caenorhabditis elegans, Coulson, et al., PNAS 1986 Oct; 83(20): 7821–7825.
Landmark 2: Yeast Artificial Chromosomes
Restriction fragment clones are good for relatively short range sequencing, but they aren’t capable of mapping sequences on the scale of millions of base pairs. Larger clones for mapping were made possible by the development of yeast artificial chromosomes (YACs) in Maynard Olson’s lab.
Cloning of large segments of exogenous DNA into yeast by means of artificial chromosome vectors, Burke, Carle, and Olson, Science May 15;236(4803):806-12.
Landmark 3: Sequence-tagged Sites
Eric Green, the current director of the National Human Genome Institute at the NIH, did critical work with Maynard Olson to develop a clever mapping method called sequence-tagged sites. The technique involves using PCR primers to identify landmarks in cloned fragments.
A common language for physical mapping of the human genome, Olson, Hood, Cantor, and Botstein, Science 1989 Sep 29;245(4925):1434-5.
Chromosomal region of the cystic fibrosis gene in yeast artificial chromosomes: a model for human genome mapping, Green and Olson, Science 1990 Oct 5;250(4977):94-8.
Landmark 4: Automated 4-color sequencing
Automating DNA sequencing was a critical step to scale up capacity. With automated methods to read sequencing output, you also needed computational methods to assess the quality of that output. Phil Green developed a prototype of these methods (notably PHRED) here at Washington University, before he moved to the University of Washington in Seattle, along with a number of other former member of the WashU Genetics Department.
Fluorescence detection in automated DNA sequence analysis, Smith, et al., Nature 1986 Jun;321(6071):674-9.
Base-calling of automated sequencer traces using phred. II. Error probabilities, Ewing and Green, Genome Res. 1998 Mar;8(3):186-94.
An improved method for photofootprinting yeast genes in vivo using Taq polymerase, Axelrod and Majors, Nucleic Acids Res. 1989 Jan 11;17(1):171-83.
Yeast genome sequenced
As Mark Johnston explains, it was necessary to sequence the yeast genome because, if you were going to use YACs in yeast as your physical vector for C. elegans or human genome sequencing, you needed to identify the yeast sequences so that you could throw then away. The yeast genome was the first sequenced eukaryotic genome.
Complete nucleotide sequence of Saccharomyces cerevisiae chromosome VIII, Johnston, et al., Science 1994 Sep 30;265(5181):2077-82.
Life with 6000 genes, Goffeau, et al., Science 1996 Oct 25;274(5287):546, 563-7.
Watch Mark’s talk below:
Transcript of “Genomics Instantiated: A View from the Front Row”, Mark Johnston, May 21, 2023, Washington University in St. Louis Gary D. Stormo Symposium
My talk today really has nothing to do with Gary. That's because I don't know any computational biology and all the other speakers before me have amply phrased Gary's accomplishments and his contributions to our field. So I won't do that. I'll just preface my remarks by saying that I know that Gary was well known from the very beginning of the field. I was a graduate student in 1978. We were doing some sequencing and we had a little bit of sequence you know 100 bases or something and we didn't know how to analyze it. And I remember somebody telling me, I can't remember who, but I clearly remember them saying, “Oh you should talk to this guy Stormo in Colorado. He knows how to analyze sequence.” I never found his email address so I wasn't able to get in touch with him.
What I want to do today is to give you a history of why Washington University and in particular the Genetics Department here was really the founder of the field of Genomics. So my talk is “Genomics Instantiated.” Now that word “instantiated”, academics love that word. I've seen it all over the place. I've never used it and I'm an academic and I've always felt bad that I've never been able to never had an opportunity to use the word instantiated. So I want to thank the organizers for inviting me to give me the chance to actually use this word for the very first time now. Of course I had to look it up because I don't really know what it means. I had to look it up. And I looked up in the dictionary: “Instantiate - to represent an abstraction by a concrete instance.”
What I'm going to present to you today is my contention that the first instantiation of genomics happened right here up on the eighth floor of McDonnell Sciences building. I'm going to tell you the story of how that came to be and how WashU came to be known as a DNA sequencing Power, and my view from the front row. I had the privilege to observe all of this. I saw the whole story from the very front row, so I'll tell you my view of what of how it all happened.
So back then, this is the ‘80s we're talking about, the goal was to map genomes. And so you have your genome here and the goal is to get a single-nucleotide resolution map of the genome. Well, back in the 80s of course you couldn't do that directly. You really can't quite even do it now directly. What you need is to map the genome first before you get it down to single-nucleotide resolution. You have to cut the genome up into smaller pieces, figure out where they lie in the genome, and then you can get your single-nucleotide resolution map. And it was those methods that you need to map the genome.

And how to do that was really instantiated here in the Department of Genetics by this guy Maynard Olson, a faculty member who arrived here I think in 1978. And Maynard was really the first one to do genomics, the first one to study an organism on the whole genome scale. And what Maynard did was to to map clones of the yeast genome. He was the first one, along with John Sulston, who you'll hear about in just a minute here, to lay out the need, plus the mechanism of the approach for how to map clones to genomes.

What Maynard did was simply do a restriction site digest of a large number of clones and measure the fragment sizes. So here's a bunch of clones of the yeast genome cut with EcoRI and HindIII, run out on a gel to size the fragments. And you just count the sizes of the fragments. If you do that enough times to enough clones, you can identify clones that overlap. They share fragments of the same lengths, and so those clones must overlap. So if you're clever enough to be able to run gels that can accurately size DNA fragments, and then you're clever enough to write algorithms that can handle the data and put it all together, you end up with something that looks like this a clone map of the genome, where the horizontal lines are individual clones, the hash marks on the clones are EcoRI and HindIII sites. And so you can generate a series of clones that map physically map the genome, and Maynard was the first guy to do this.
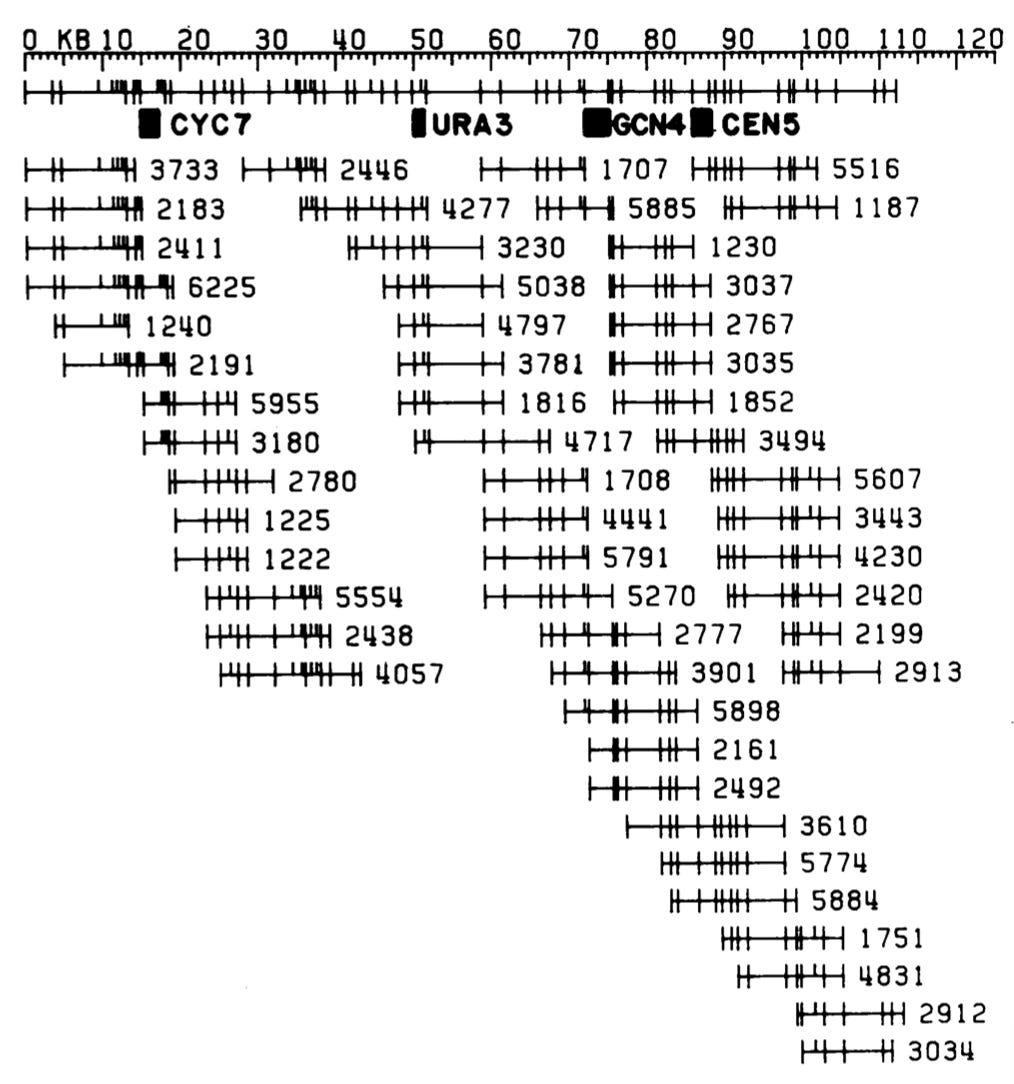
And he was doing it at a time when nobody could understand why you'd want to do that. I remember a very well-known scientist, a very smart guy who said to me who the hell cares where all the EcoRI and HindIII sites are in the yeast genome, I don't really care. Well, the reason you care is because you need a map of a genome to get a sequence of a genome, and all that follows from that.
Okay, so Maynard was the first one to map genomes. Maynard was working at this level, in the range of clones of about tens of kb in phage vectors and plasmid vectors and later on in cosmid vectors. He wasn't working at the larger scale of thousands and hundreds to thousands of kilobases of DNA. So now comes the key event that really led to WashU having a Genome Sequencing Center. You all know that it's much easier to put together a puzzle with a few number of pieces than a puzzle with lots of pieces, right? A thousand-piece puzzle is much harder to put together than a hundred-piece puzzle, and Maynard was working in this range, and then comes the key event.
Bob Waterston, Maynard's colleague and my colleague up on the eighth floor of McDonnell Sciences Building, goes off in the mid 80s, ‘85 I think, ‘86, to do a sabbatical with John Sulston. And Bob's over there working on his muscle genes in John's lab, watching John map the C. elegans genome. John was doing the same thing Maynard was doing, trying to get a map of the C. elegans genome, eventually for the purpose of sequencing it. And John was also mired in this area of small fragments. He had 750 contigs and there were 750 gaps in the clone map, when he should have had seven. And he just couldn't get past those 750 gaps in the DNA sequence. Bob is watching John be frustrated with that.
Bob comes back to St Louis and he talks to these two guys, David Burke and George Carl. They were graduate students in Maynard's lab, and they told Bob about work they were doing to generate yeast artificial chromosomes. These were vectors that would take large pieces of DNA, and Bob learned about this before it was published. Bob goes back to John Sulston’s Lab in Cambridge England and begins to work with John on closing those 750 gaps in the genome sequence. And that's really what got Bob into DNA sequencing, which is what brought a genome sequencing center with hundreds of millions of dollars in grant income to Washington University.

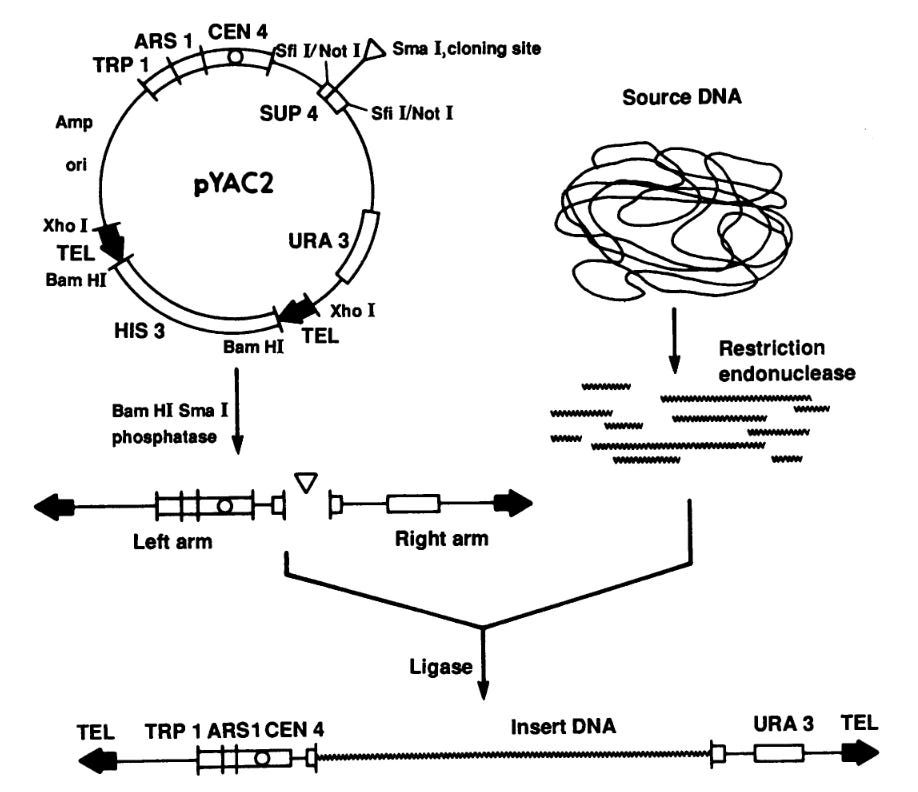
Okay so there's another landmark [to talk about]. We have clone mapping from Maynard and John Sulston, we have yeast artificial chromosomes from David Burke and George Carl, again working in Maynard’s lab, and there's a third major landmark in genome mapping that also came out of Maynard’s lab called sequence-tagged sites. Maynard, in 1989, publishes this paper, with a few other people to give it credence I guess, “A common language for physical mapping of the human genome.”

Sequence-tagged sites are simply PCR priming sites that will yield a PCR product. So you simply get random sequence from a bunch of clones, design primers, and if those primers give a product, amplify a sequence, then that means the clone that was the template has those sequences in it. So it simply sequenced landmarks of about 100 to a thousand base pairs. Sequence-tagged sites, really a brilliant idea, quite simple, which as most brilliant ideas are, they're brilliant after you know what the idea is.
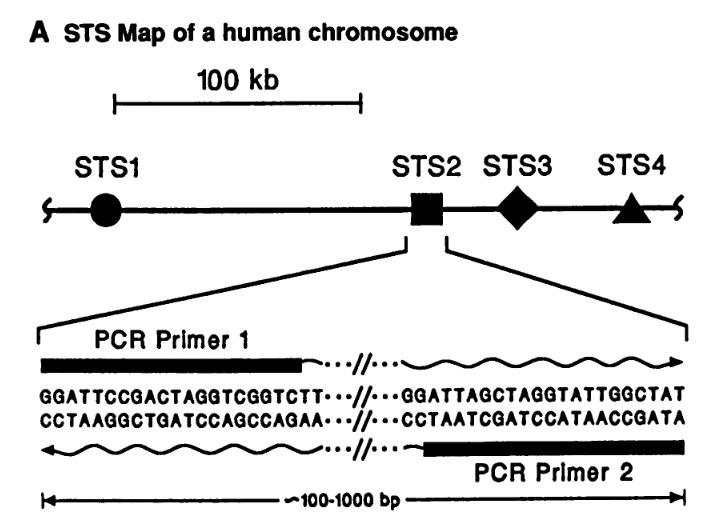
The guy who put sequence-tagged sites into practice, who instantiated sequence-tagged sites, was this guy Eric Green, a postdoc with Maynard. Eric was a student here, an M.D./P.h.D. student, got his degree in immunology, and decided he wanted to go into genomics and join Maynard's lab. And he really put into practice Maynard's idea of sequence tagged-sites and ended up generating, by 1990, a map of a region of the human genome. It was a model for how you map the human genome with sequence-tagged sites. Here's all the clones [image below], the horizontal lines, and now those dots on the clones are sequence-tagged sites, PCR priming sites that are present in those clones. You generate a map of the genome that way. Eric went on to become the second director of The National Human Genome Research Institute where he has been the director now for 15 years.
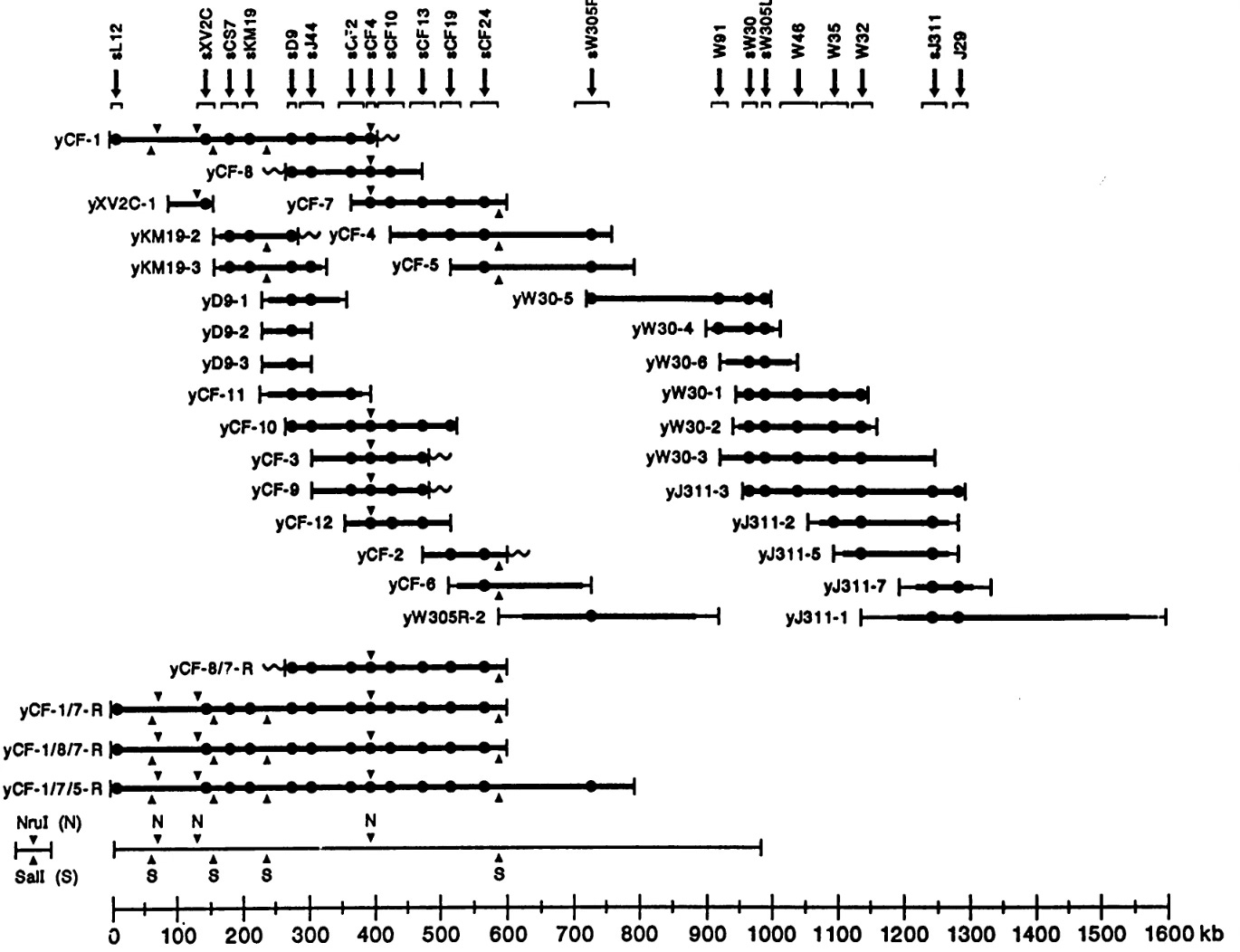
So genomics was born in the [Washington University] Genetics Department, was extended by the Sequencing Center in the Genetics Department, and then we exported it to the National Human Genome Research Institute. Mr. McDonnell [James S, McDonnell] would have been proud that his money invested in the Genetics Department really came to fruition.
Okay, so now we got a map, and now we're ready to do the sequencing. You all know how this works, right, di-deoxynucleotides get incorporated, cause chain termination, you generate a family of molecules that have each stopped at a nucleotide, you separate those by their size on a gel and you read the sequence off. Now this was how it started for C. elegans sequencing. I remember them developing films and reading off the sequence. I remember you know fishing gels out of the fixer and reading the sequence before they were even dry, because you couldn't wait to to see your exciting sequence come off. Now of course you're not going to be able to sequence a genome that way. You’ve got to have some automated way to do it.
{kind=link}
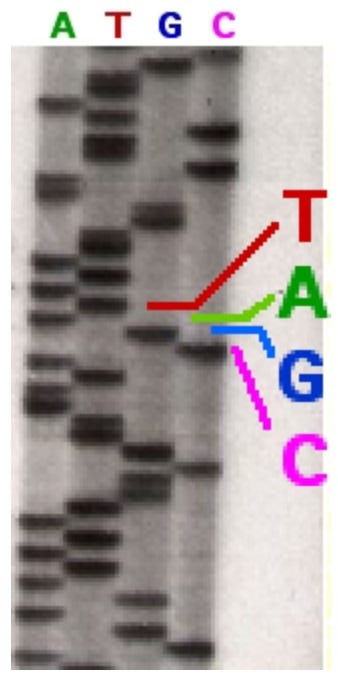
So a great leap forward came with the development of fluorescently-tagged DNA for sequencing where you put on your di-deoxys some dyes that report a color, and now you can load all of those reactions into one lane and simply read off the sequence from the color of each of those bands. So that was a major advance that allowed automation and sort of portended that the sequencing the human genome was going to be possible. You get these kinds of kinds of gels where you read off the sequence and here's really what the readout was. These colored peaks are the peaks of those bands coming off the gel, and you just simply read the sequence off from the color.
But the problem is, where do you start your sequence read. Down here it's not going to be a very good sequence, it gets pretty good in here, but then the sequence starts degrading, so where do you stop reading your sequence. And here's where a major advance came that really enabled the human genome sequencing and it also comes from the Department of Genetics on the eight floor of McDonnell Sciences building. That is the development of quality statistics by Phil Green who was a faculty member in Genetics.

Here's Phil, and what Phil did is develop algorithms that would read those peaks, those colored peaks, and put a quality score on them. So his algorithm could read the peaks and tell you how sure of each base call you are. So a score of 10 means that there was a one in 10 probability the base was called wrong, so you're 90% certain that base is called right. A score of 50 said that there was a one in 100,000 chance that you were wrong so you're most certain of that of that base call. And so that enabled you to turn these peaks into scores which enabled automation of the sequence reading, and that was a major advance in fluorescent sequencing of the human genome. [Note: Phil Green moved from Washington University in St. Louis to the University of Washington in 1994, bringing with him the protoypes of PHRED and PHRAP, initially developed at WashU, and which he later published at the University of Washington.]
There were other advances this is the slide I got from Maynard. These are Maynard's landmarks in the evolution of four-color sequencing. There were advances in polyacrylamide gel technology, better dyes that gave you more sensitive detection , DNA polymerases that would accept better the dye-labeled nucleotides. And there's one more advance that was critical that, again also came from Washington University. This is one not from the McDonnell Sciences building, but from the first floor of the North building in the biochemistry department, and that was the development of cycle sequencing: using PCR technology to amplify your sequencing reaction so you can sequence small amounts of DNA. And that was done by our late colleague John Major and his student Jeff Axelrod.

So here's John, and what Jeff and John did was they use multiple rounds of anealing and extension with Taq polymerase to detect sequences in the genome. You do a one-sided PCR reaction, essentially a linear amplification of the reaction, and John pointed out that their primary extension assay could be used to determine DNA sequence directly from the yeast genome. That was the first instantiation of cycle sequencing, which was another major advance that enabled the sequencing of the of the human genome.

So mapping a genome happened here, many other advances happened here at Washington University. So why am I up here telling you the story? It's all about Maynard and Bob and Phil. Right, why am I here? Well, I had a front row seat because I was peripherally involved in the project. So when Bob set out to sequence the worm genome, he and John decided they needed to get the sequence of the yeast genome also. Why? Well, they thought that they were going to be sequencing C. elegans DNA cloned in YACs. And if you isolate YAC DNA from yeast, you're going to necessarily be contaminated with yeast DNA. So you got to know the yeast sequence so you can throw it out.
So they wanted to sequence the yeast genome and they recruited me to be in charge of that of that project. So this was our first paper on this in 1994, we sequenced one of the yeast chromosomes. This was the second whole chromosome sequenced and that's why it was published in a relatively high, in a sensibly high-profile Journal. We did it in quite quick order because we had Rick Wilson’s and Bob Waterston’s Sequencing Center that enabled us to do that.

Now what does it mean to manage a project like that? So my role to manage this project was to rely on Linda Riles. Linda was Maynard's technician who played a big role in his mapping of the yeast genome. So Linda was the caretaker of all the clones of the yeast genome. Here's Linda in front of the maps of the yeast genome.

So my role was to go tell Linda what chromosome we were going to sequence next Linda would go in and figure out what clones span the chromosome. She'd give them to me, I'd walk them the three blocks over to the 4444 building, hand them to Lucinda [Fulton], and they'd get sequenced. The sequence would come in and I had the privilege of sitting in front of a computer and annotating it, which was really fantastic and I got all the credit. It's great work if you can get it, highly recommended.
Then just a little while later we collaborated with a worldwide Consortium of sequencers — back then sequencing was hard and so lots of people were involved — to produce the sequence of the first eukaryotic genome, yeast, about 12 megabases in size. This was an interesting sociological and political science experiment, which we can talk about later, maybe.
Then soon thereafter, Bob and John's Sequencing Center sequenced a real genome, you know, a large genome [C. elegans]. About 100 megabases is about roughly 10 times the size of of yeast. The first multi-cellular organism whose genome was sequenced. And then of course you know that they sequenced the human genome. Here they are in 2000 celebrating the completion of the yeast genome. Here's Bob Waterston and Rick Wilson at the White House, with a few other minor players in the process, celebrating what they called the completion of the human genome sequence.

So really this guy [Bob Waterston], was I think one of the moral compasses of the project, for data release, for appropriate allocation of the resources of the project. He really, I think, does not get all of the credit that he deserves for his leadership role, his quiet leadership role in that project. Here is Bob at a press conference with Craig talking about talking about the sequence.
That's how genomics was instantiated in the field, how genomics was invented, I claim here, at Washington University on the eighth floor of the McDonnell Sciences building by Maynard, implemented extraordinarily well by Bob, and advanced by people like Phil Green. So we should all be proud to have been part of Washington University, and I had the great privilege of having a front row seat for all of that which I've just told you about.
Mike, the internet has been around for 30+ years, but encountering this post was the first time I found someone talking about me while I was just browsing through random feeds. The 1980's was a great time to be a member of the James S. McDonnell Department of Genetics. My stay in St. Louis (1979-1992) spanned the whole decade. Your post will help future historians reconstruct events that occurred before the term "genomics" had even been coined. I hope you will keep up "This Genomic Life," although I am sure it is a distraction from your research, teaching, and other resonsibilities. Since I retired from the University of Washington (U. Wash not Wash U.!) in 2008, I have largely pursued long-term interests in the history and philosophy of science. To make sense of the genomics literature today, I need a guide who is in the thick of the fray. I look forward to using TGL for the purpose. Best regards, Maynard Olson