

Can generative AI write genomes on demand?
A reality check for generative DNA models

If you scanned the headlines of some leading science outlets the other week, you could be forgiven for thinking that the generative AI can now design a working genome. Here is a story in Nature describing the release the Arc Institute and NVIDIA’s’s new foundation model, Evo 2:
This story reached beyond the bounds of the scientific community and was even mentioned on The Ezra Klein Show this week. But can Evo 2 (or any generative AI) design completely new genomes that actually function? The answer is that we have no idea. Nobody has shown it yet.
I’m not writing this post to pick on Evo 2. Brian Hie, Patrick Hsu, Hani Goodzari and the Arc Institute team (working with NVIDIA) are pushing the envelope of genomic foundation models. Their innovations in model design are described in a companion paper to Evo 2. I am enthusiastic about this work. But we need to be clear: while ever larger generative AI models (40 billion parameters for Evo 2) can natural-looking sequences at scale, there is very little evidence–and in some cases none at all–showing that these sequences function as expected. The rate-limiting step in genome design is still the experiment.
So why are we hearing claims that generative models are writing genes and genomes? At this point, the field largely relies on comparisons to existing datasets, rather than a thorough program of experimental testing. In the case of Evo 2, the team prompted the model with various sequences,such as a bacterial genome, and then examined the generated sequence to see how well it resembled natural sequences. In the case of the generated bacterial genome (prompted with the very small M. genitalium genome), the authors show that a model-generated 580 kb sequence has a gene density resembling the natural genome, and that the synthetic gene sequences show structural matches to natural enzyme genes.
But could this genome function coherently, with properly regulated, fully-functioning genes? We won’t know until someone synthesizes the entire thing and puts it into a bacterial cell. The experiment is feasible with today’s technology (actually with 2008 technology), but it is resource intensive. My intuition is that no generated genome will actually function without a lot more tinkering to make it work, or without training models in a different way (more on that below). I could be wrong! Be we don’t know because the experiment hasn’t been done.
Here is a more specific example of one of the problems. The Arc team had Evo 2 generate a mitochondrial genome. For those not familiar with mitochondrial genomes, they are independent, mini genomes present in the eukaryotic cells’ mitochondria. They encode a handful of genes, many of which work in complexes.
Evo 2 generated a set of mitochondrial genomes that seemed to have the right complement of genes. But there are three issues. First, we don’t know which of the generated genes are actually functional. They resemble the natural mitochondrial genes, but they may have variation in them that leave them inactive. Second, regulation of genes in the very compact mitochondrial genome is complex, and we have no idea whether Evo 2 produced functional regulatory sequences. And third, even if we assume that all these genes are indeed functional, each one most closely resembles a natural gene from a different species, as seen in Table S6 of the paper:
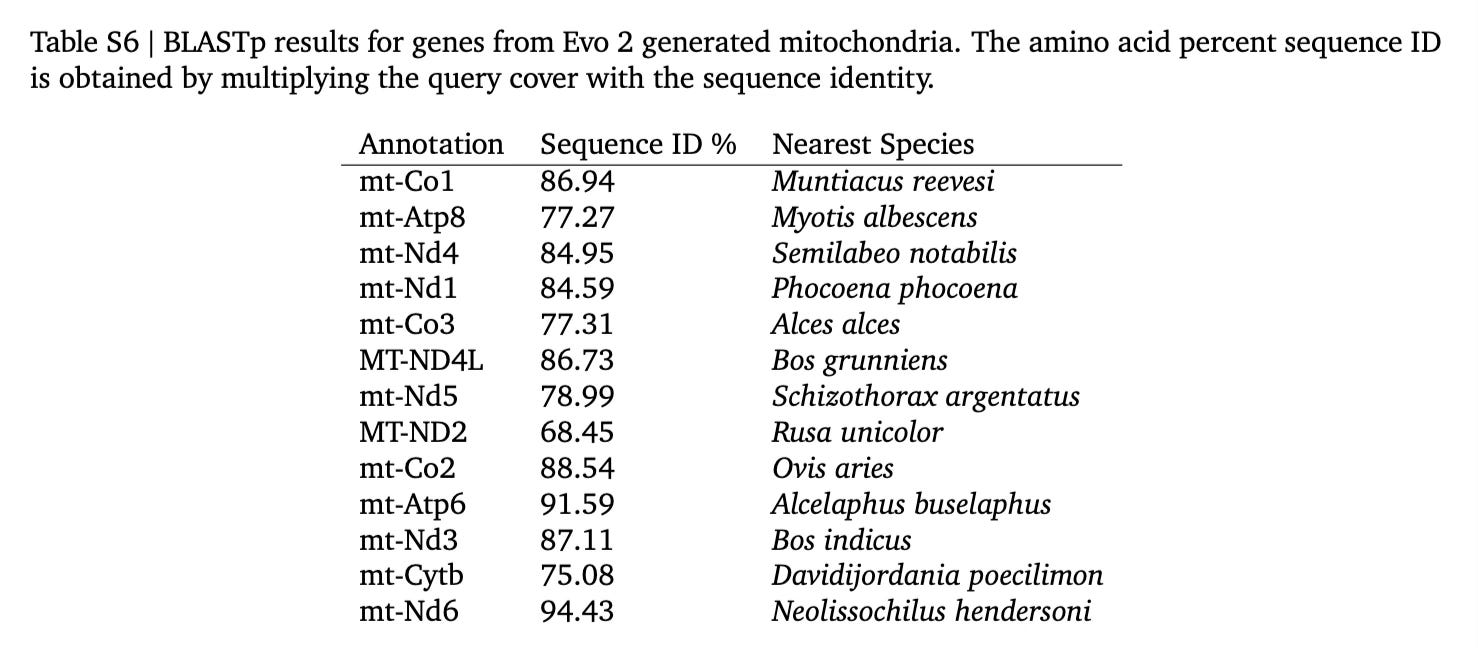
Those species are the muntjac (a deer native to China), a type of mouse-eared bat, a species of labeonins (freshwater fish), a harbor porpoise, a moose, a yak, the Balkhash marinka (freshwater fish), the Sambar deer, the domestic sheep, a species of antelope, the zebu (a type of cow), a species of eelpouts (marine fish), and a species of carp found in Thailand. While these are all vertebrates, and mitochondrially encoded genes are generally well-conserved, I am very skeptical that you can put together a functioning electron transport chain with a mix of fish and mammalian genes.
The problem is that Evo 2, trained on over 8 trillion bases of sequences from many species, may not have learned how different members of a complex within a single species genome work together. Yes, Evo 2 learned which genes go together in the mitochondrially encoded genome. But the 45 carp genes for mitochondria Complex I have evolved to work with each other in carp cells, and the 45 harbor porpoise genes evolved to work each other in porpoise cells. The carp genes did not evolve to work with the porpoise genes-and Evo 2 probably doesn’t know that.
Again, I could be wrong, but until the experiment is done, we do not know how realistic the genomes generated by Evo 2 are. They could be genuinely functional, or they could be like the non-sensical AI-generated engine blueprint up at the top of this post. We just don’t know until we’ve done the experiments.
To be fair, the Evo 2 team is working on a set of experiments, and in their Evo 1 paper last fall, they tested some designed CRISPR-Cas complexes and a new transposable system. But AI-designed sequences at the scale of even a small genome have not yet been tested.
One of most successful gene designers is the recent Nobel laureate David Baker, who has spent decades investing in tools for both careful design and experimental synthesis and testing. In their most recent preprint, the Baker lab tested their AI-designed peptide inhibitors of the proto-oncogene Ras. They characterized the designed proteins in vitro, and showed that these inhibitors bound their targets in live cells.
Thorough experimental testing needs to become the standard in this field. I was surprised to see a paper last fall in Genome Research, which claimed to design realistic sequences but did not show that any of them function. Again, this paper was from a great team (at Genentech) whose work I admire, and I understand the value of papers that report innovation in model architecture and training. There are non-trivial computational problems to solve. But without experiments, we do not know whether these models work at all.
I suspect that large models trained on large sequence datasets will not be enough. There are real efforts to design and physically build synthetic genomes, the most ambitious of which is the yeast Sc2.0 project. It has taken years of debugging and re-synthesis to build a synthetic yeast genome, which is, by eukaryotic standards, pretty small. AI design will require a lot more human intervention to be successful, at least in the near future. Successful design will also require skilled experimentalists who can show that the designed sequences work.