

Are we making AI too human?
A big goal of AI is to achieve human-like intelligence but we may need something else for applications that aren't well-suited to human intelligence.
If you pay any attention to AI in the news you know that many influential people believe that AGI (artificial general intelligence) is on the horizon. In early March, The New York Times’ Ezra Klein said on his podcast that:
For the last couple of months, I have had this strange experience: Person after person — from artificial intelligence labs, from government — has been coming to me saying: It’s really about to happen. We’re about to get to artificial general intelligence.
Klein defines AGI as AI that is “capable of doing basically anything a human being could do behind a computer — but better.” Achieving AGI is clearly a major goal of the big players in AI. Google, clearly concerned about being perceived as responsible in its quest for AGI, recently released a paper on AGI safety. The underlying premise is that work pursued by Google and others is definitely on the path to AGI.
George Mason University economist Tyler Cowen also thinks AGI is imminent, and he also defines it in terms of human intelligence:
Others are skeptical that there is any clear threshold that would count as achieving AGI. Arvind Narayanan and Sayash Kapoor, authors of AI Snake Oil, argue that we’ll see AI models climb a “ladder of generality,” with new models capable of new tasks; however, they are skeptical that we’ll get to anything one might call AGI simply by building bigger LLMs (large language models):
An unknown number of steps lie ahead before we can reach a level of generality where AI can perform any economically valuable job as effectively as any human (which is one definition of AGI).
Why all the fuss about AGI? A big part of the answer is that AGI has been the holy grail of AI throughout its entire history because the field is specifically motivated by human intelligence. There are many ways that you can use probability and statistics to build powerful models of the world. But the AI field, starting at least with the very first artificial neurons has proceeded on the premise that we can learn how human intelligence works by building computer models with similar capabilities. In other words, one purpose of AI is to simply understand how intelligence works–and thus AGI would represent an important milestone.
But AI clearly has value when it’s applied to many tasks that humans don’t do especially well. And so it’s worth asking, is the focus on human-like capabilities holding back AI progress in applications that don’t depend on recreating features of human reasoning? To be more specific, in the context of genomics, are AI architectures cribbed from language models and image recognition tools really the right way to go?
Borrowing a Jetsons analogy from Max Bennet, are we wasting effort trying to build a humanoid robot that can hold a conversation and clean the house (left) when what you really need is a one-armed robot (right) that can do complex but specialized tasks in a factory?

I don’t pretend to have a serious answer to this question, but it seems useful to raise it. In the rest of this post I want to explore the question by thinking about thoughtful benchmarks. To measure progress and spur innovation, we need to think carefully about tests of AI that are not merely based on whatever evaluations are convenient to make, but rather on tasks that are specifically designed to reflect our big goals for AI. The punchline is that progress in biological applications of AI is going to depend on devising much better ways to test our models.
Benchmarking AI on fluid intelligence
While Tyler Cowen thinks AGI might be here in a few days, AI scientist François Chollet does not. The Atlantic recently ran a story profiling Chollet, called “The Man Out to Prove How Dumb AI Still Is”. The piece is largely about a famous set of benchmarks that Chollet created with his collaborators, ARC-AGI. (ARC stands for Abstraction and Reasoning Corpus.) The ARC benchmarks are based on an interesting 2019 paper by Chollet called “On the Measure of Intelligence.” He argued that most tests of AI’s capabilities overestimate how good it is, because they they are too heavily based on prior knowledge:
[S]olely measuring skill at any given task falls short of measuring intelligence, because skill is heavily modulated by prior knowledge and experience: unlimited priors or unlimited training data allow experimenters to "buy" arbitrary levels of skills for a system, in a way that masks the system's own generalization power.
Showing that GPT can score in the 90th percentile on the LSAT is not really a significant test of intelligence, because the GPT was trained on the entire corpus of the internet. What we should be measuring, Chollet argued, is the capacity to solve problems that don’t depend on lots of prior skill and knowledge, something called fluid intelligence. The ARC benchmarks were designed to test fluid intelligence and, as the Atlantic piece points out, AI models completely bombed when they were first tested.
The ARC benchmarks have spurred innovation and AI now does much better. OpenAI’s o3 showed impressive gains, but it still fails to solve puzzles that most elementary school students could solve. And when it does solve these problems it takes on average 14 minutes of compute time to do something that takes most humans just a few moments of inspection. Here’s an example of a puzzle o3 couldn’t solve:
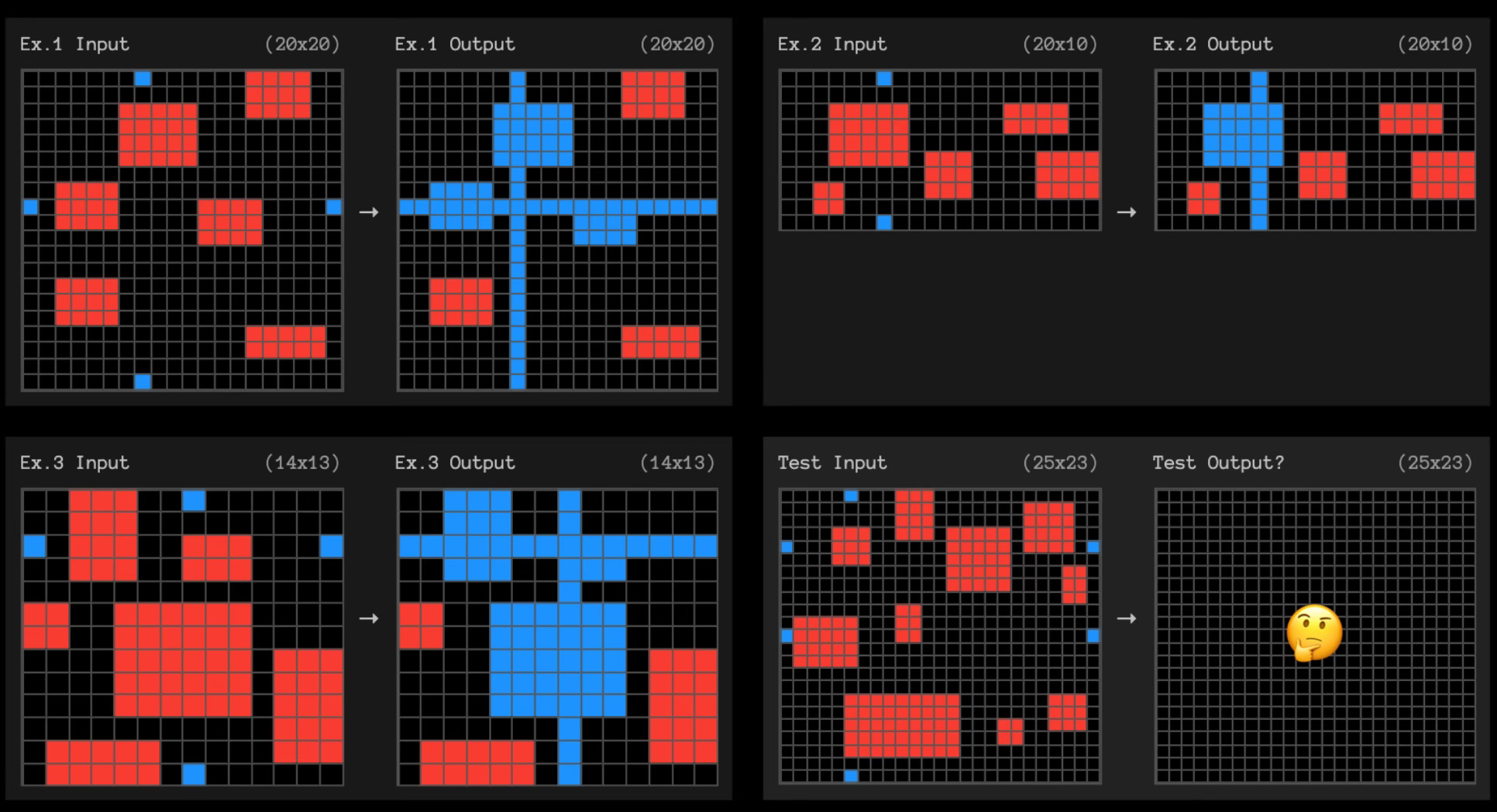
You can try these puzzles yourself. Spend a few minutes with them and you’ll quickly realize that they test features of intelligence that are much more universal among humans and more profound than what’s needed to get a high score on the LSAT.
Thinking about the ARC-AGI benchmarks is useful for a few reasons. First, it should deflate any expectations that AGI is just around the corner. My ninth-grader solved the above puzzle in a few seconds. Second, ARC-AGI shows that thoughtful benchmarks, as opposed to benchmarks of convenience like the LSAT, can spur innovation. And third, they highlight the heavy emphasis of AI development on achieving features of human intelligence. ARC-AGI is easy for humans but hard for AI. What about applications of AI that are not easy for humans? Does it make sense to rely almost exclusively on AI methods that are developed to achieved human-like capabilities?
What’s the equivalent of fluid intelligence for molecular reasoning?
One could reply to the above question by pointing to the Nobel Prize won by the Demis Hassabis and John Jumper for AlphaFold. AlphaFold’s ability to accurate predict 3D protein structures is incredibly useful, and its is based on decades of human-intelligence-inspired AI development. However, AlphaFold does include some critical innovations in its architecture, so it’s not just an off-the-shelf LLM. That’s not always true of the increasingly common genomic LLMs that seem to appear in the literature every week. Not all, but much of the AI in biology is taken almost off-the-shelf from applications in computer vision or human language.
I’m not an AI expert and definitely not qualified to discuss innovations in AI architecture. But as a field, we should ask ourselves, how can we spur innovation that’s relevant for biology? Humans are good at solving the ARC-AGI puzzles, but we’re terrible at finding subtle patterns in megabases of genomic sequence. What’s the genomic equivalent of fluid reasoning that we want genomic AI to achieve?
Right now, the field relies on the equivalent of benchmarking GPT on the LSAT. We use convenient large-scale datasets to evaluate our models. Sometimes this makes sense, because we want AI models that can accurately predict the outcomes measured in those datasets. But, to push the LSAT analogy, an AI model that gets a perfect score on the LSAT likely won’t be able to engage in real-life legal reasoning if it lacks the kind of fluid intelligence that ARC-AGI tests for. Similarly, it’s one thing for a genomic model to predict gene expression levels in a handful of cell types; it’s something else to be able to predict gene expression in any cell type, in any genetic background or disease state. One definition of genomic AGI might be AI that can replace our need to do an experiment, because the model predicts what happens in a new context with as much accuracy as our experimental measurements would have had.
Again, I don’t have the answer. But to highlight the problem, I’ll summarize some important genomic benchmarking papers that are relevant to considering where we go from here.
Protein-ligand binding AI models are still just memorizing training data
A group out of the University of Basel has introduced the “Runs N’ Poses” benchmark dataset, a set of 2,600 high-resolution protein-ligand structures not included in the training data of the latest deep learning 3D structure predictors, including AlphaFold3. They binned the structures in their benchmark dataset according to how similar the structures were to other structures in the training data. They then asked, how accurate are the models on structures that are very different from the training data, compared with structures that are similar. The results show that these models don’t generalize well:
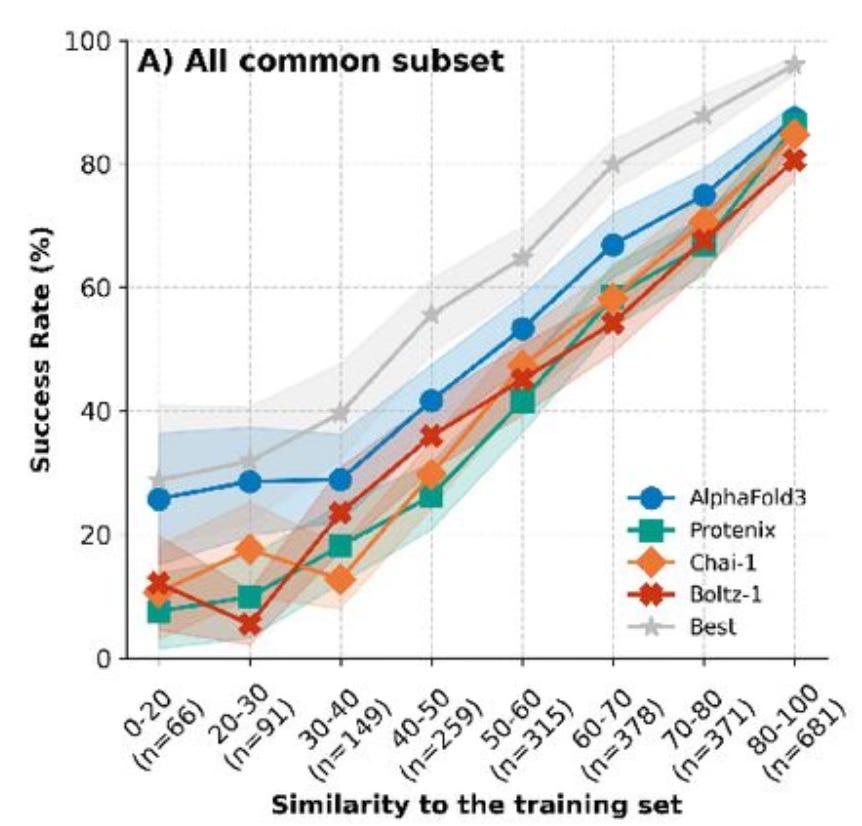
There is a big decrease in accuracy on structures that don’t look like what the models have previously seen. This is evidence that success in this area still largely comes from memorizing the training data, rather than learning the biophysical rules that govern how proteins bind ligands.
Predicting regulatory genetic variant effects: Big AI doesn’t beat simpler models
A group at UC Berkeley and Genentech has released TraitGym, a benchmark dataset of non-coding regulatory DNA variants associated with a set of Mendelian diseases or a set of complex traits. For readers not steeped in genetics, Mendelian diseases are usually caused by a variant in one gene with a large effect on the phenotype, while complex traits are typically affected by variants in many different genes with more subtle effects.
The key result is that relatively simple models based on evolutionary alignments of DNA sequences. In the plot below, performance (AUPRC) is represented on the x-axis.
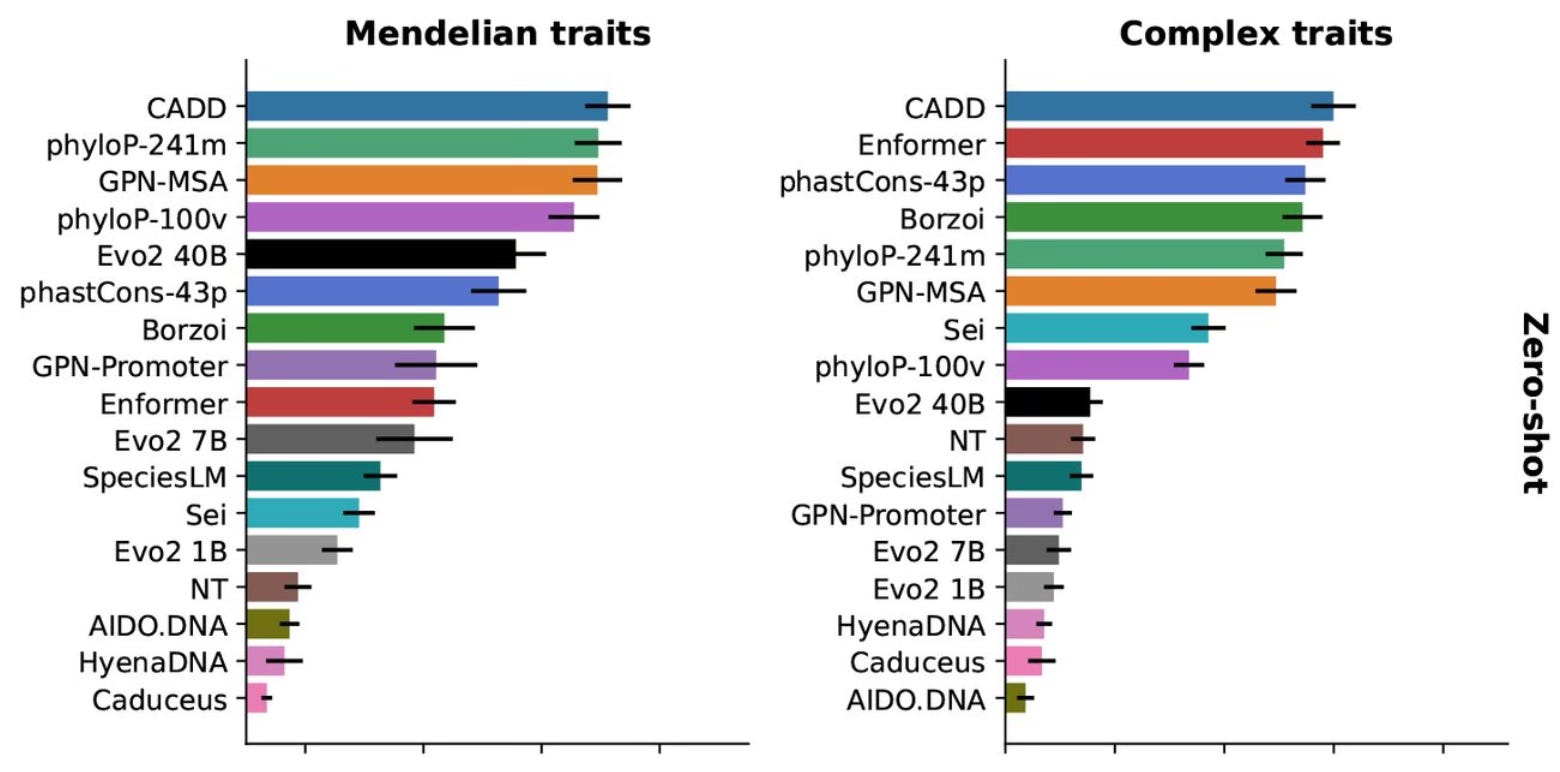
The best model, CADD, as the TraitGym authors describe it, is a “is a logistic regression model trained to distinguish proxy-deleterious from proxy-neutral variants,” built on a large set of feature annotations, some of which were derived from protein language models. Enformer (ranked #2 on complex traits) is a a supervised, transformer-based AI model. Notably, the big self-supervised AI models (HyenaDNA, Evo2 with 40 billion parameters, etc.) did much worse.
Large language models don’t outperform simpler models, again
Anshul Kundaje and his lab at Stanford found similar results in their benchmark analysis, DART-Eval. The benchmarks were designed to test “sequence motif discovery, cell-type specific regulatory activity prediction, and counterfactual prediction of regulatory genetic variants.”
There are multiple interesting results in this analysis. One suggests that language models have not learned to identify DNA sequence features that define cell type-specific regulatory DNA. The UMAP plots below show the results of clustering the model embeddings of cell type specific regulatory sequences. The models were presented with a collection of cell type-specific regulatory sequences (derived from scATAC-seq data) and tried to learn which sequences are active in the same cell type.
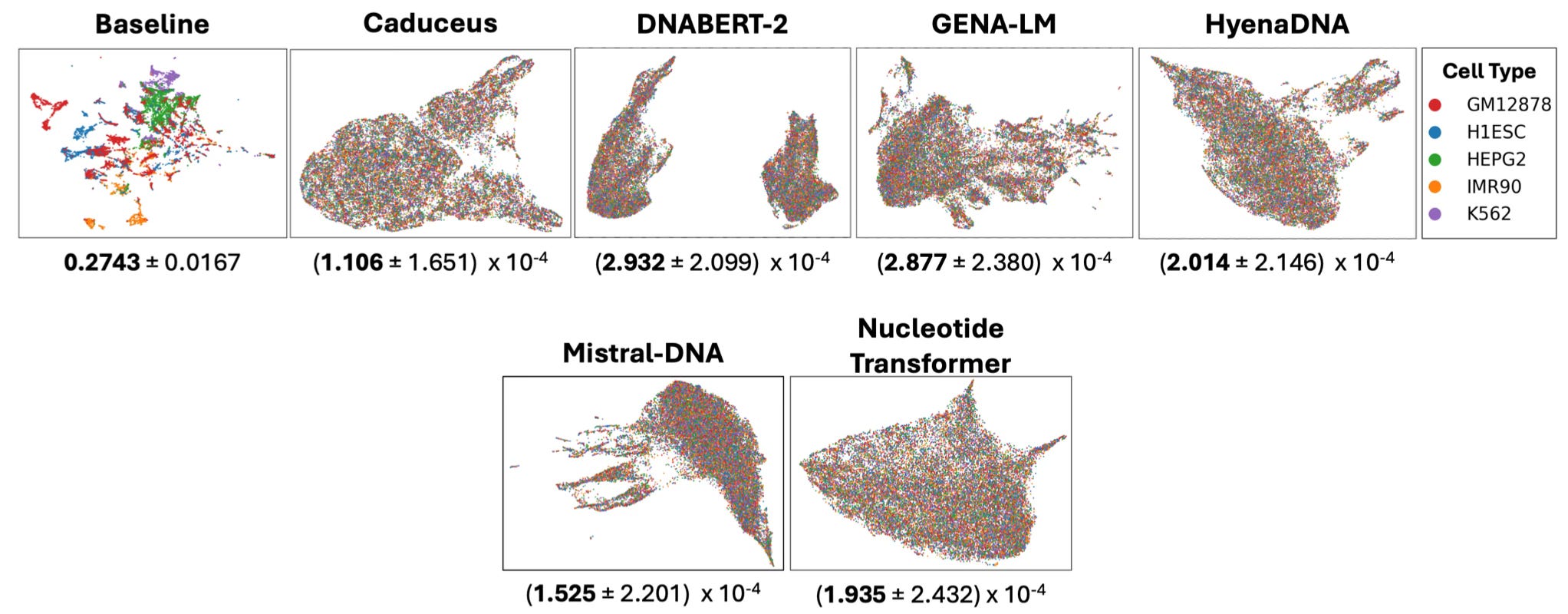
There is much more in the paper, but I’ll just cite a key conclusion:
Our systematic evaluations reveal that current annotation-agnostic DNALMs [DNA Language Models] exhibit inconsistent performance and do not offer compelling gains over alternative baseline models for most tasks, despite requiring significantly more computational resources.
Language model embeddings underperform
The last study I want to highlight is from Peter Koo’s lab at Cold Spring Harbor. The authors asked whether the more complex representations learned by language models were better at predicting the activity of regulatory DNA compared to simpler representations based on one-hot encoding. The question is whether the language models learned a good (and generalizable) representation of the underlying DNA sequence grammar. The answer is that simpler representations do better:
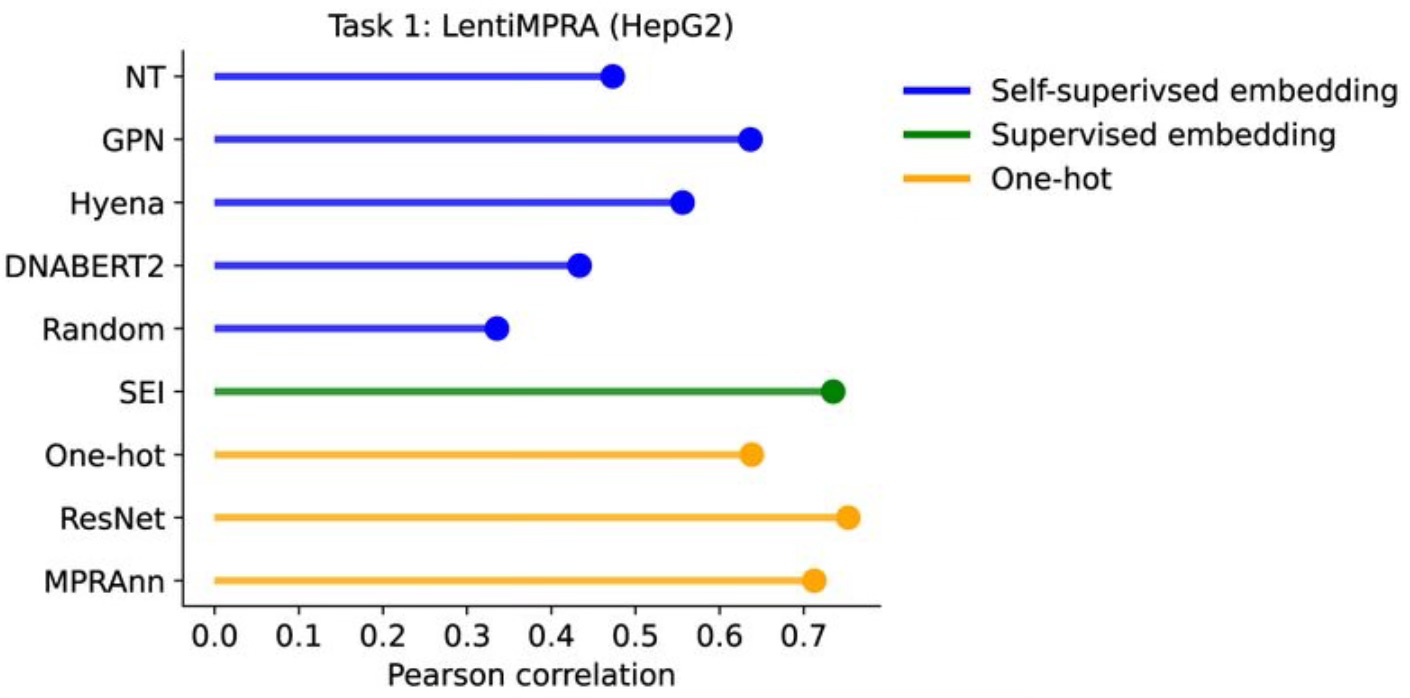
Their conclusion:
To assess the transferability of knowledge acquired during pre-training for current genome language models, we evaluated the predictive power of pre-trained representations from four gLMs on whole genomes (without fine-tuning) across six functional genomics prediction tasks with appropriate baselines for comparison. We found that within cis-regulatory elements, representations from pre-trained gLM provide little to no advantage compared to standard one-hot sequences.
There is much more to discuss, but this post is already getting too long. What the results above illustrate is that very large models–the GPTs of genomics–don’t seem to be learning general representations of protein-ligand interactions or DNA sequence grammars. They’re not learning the biology, and in many cases, simpler machine learning tools outperform the big models. We’re far from AGI for biology, whatever that might mean. To spur innovation, we need more benchmarking analyses like those above.
Perhaps this should include new experimental datasets that are specifically designed, like ARC-AGI, to test whatever the equivalent of fluid intelligence should be for genomic reasoning. Our goal should be to achieve AI that learns meaningful representations of fundamental biology that generalize across contexts. Rather than aiming for AI that’s can do anything that humans can do, but better, in genomics we need AI that can accurately predict anything that humans can measure in an experiment, but haven’t.